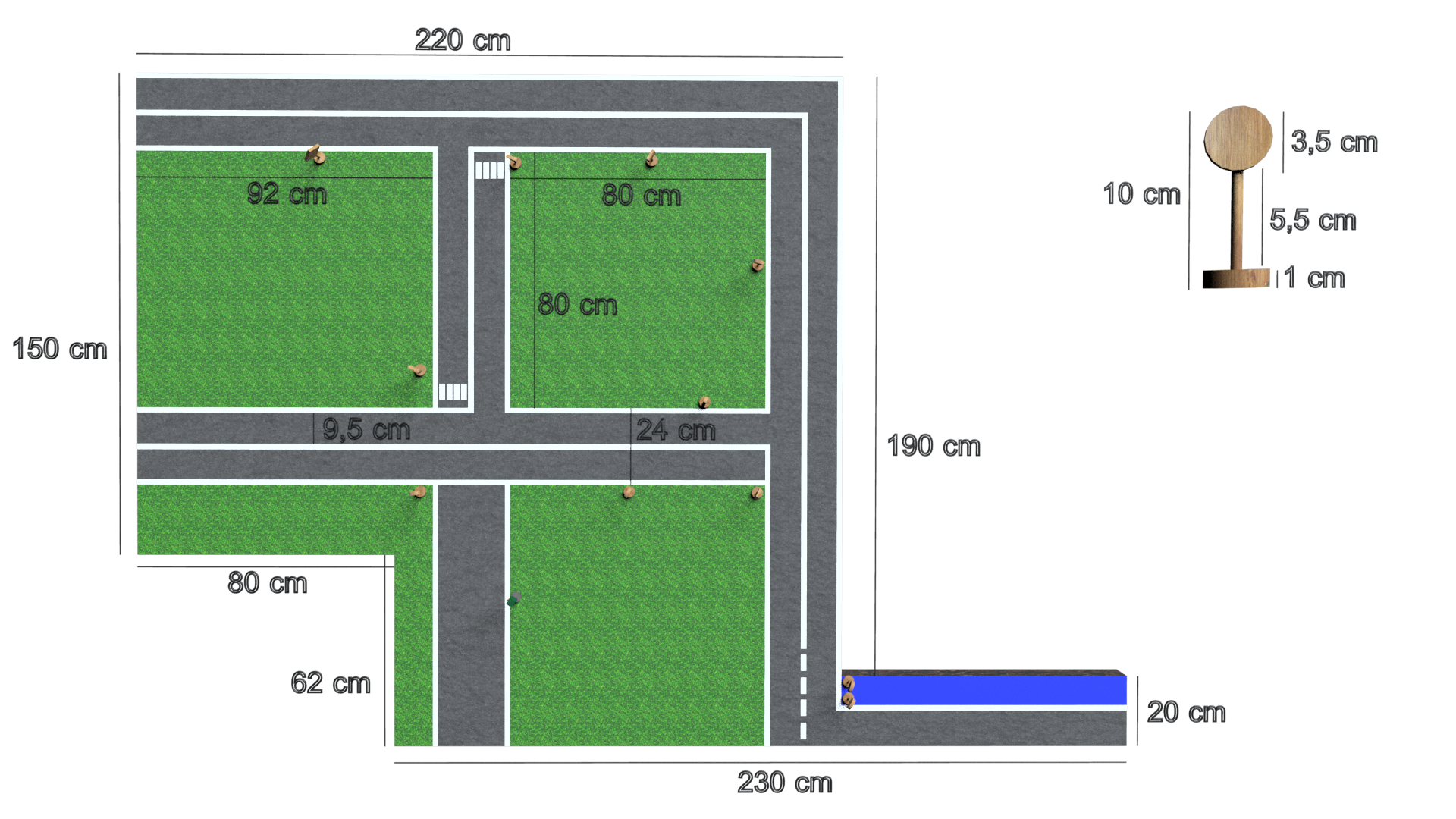
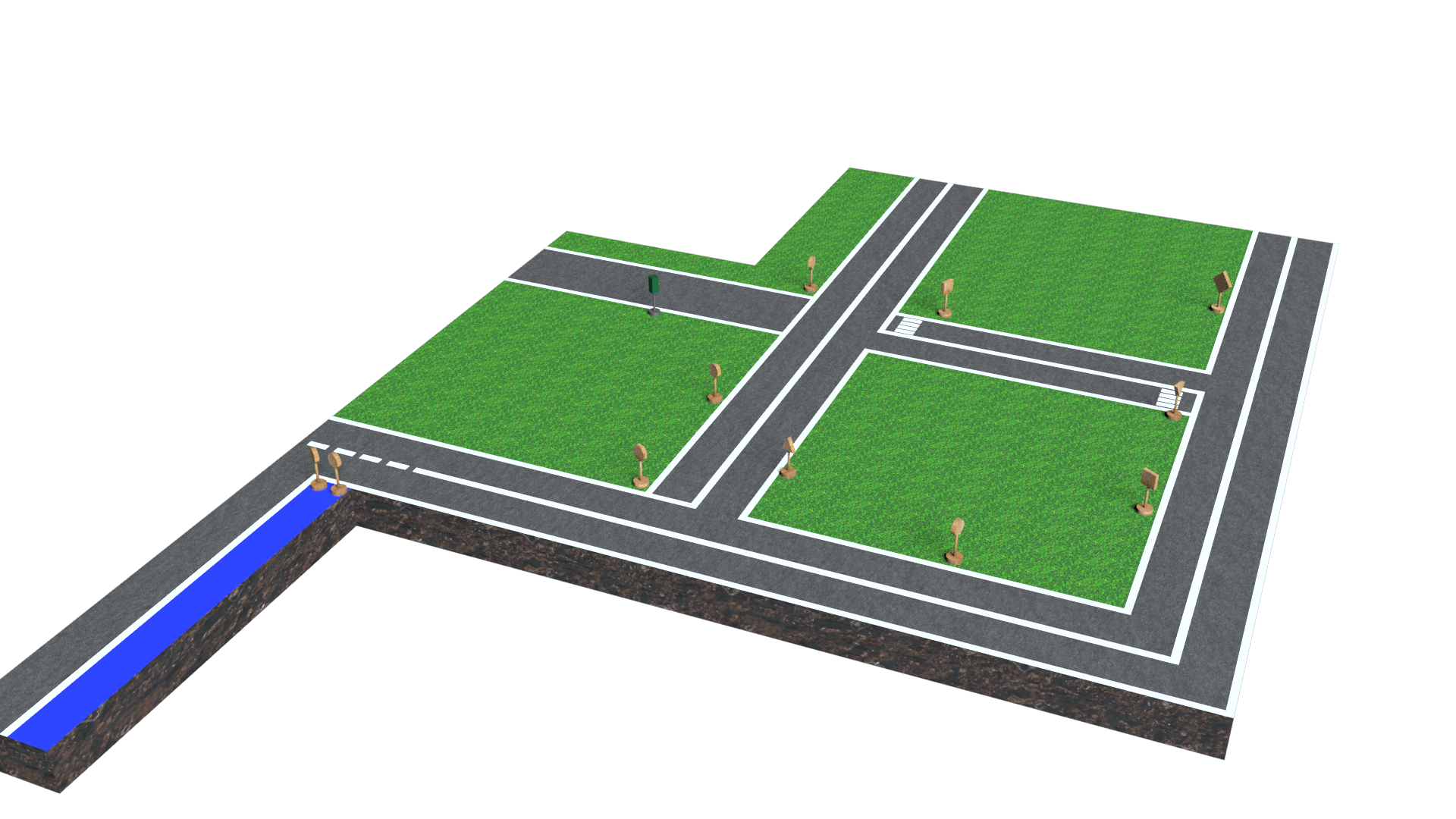
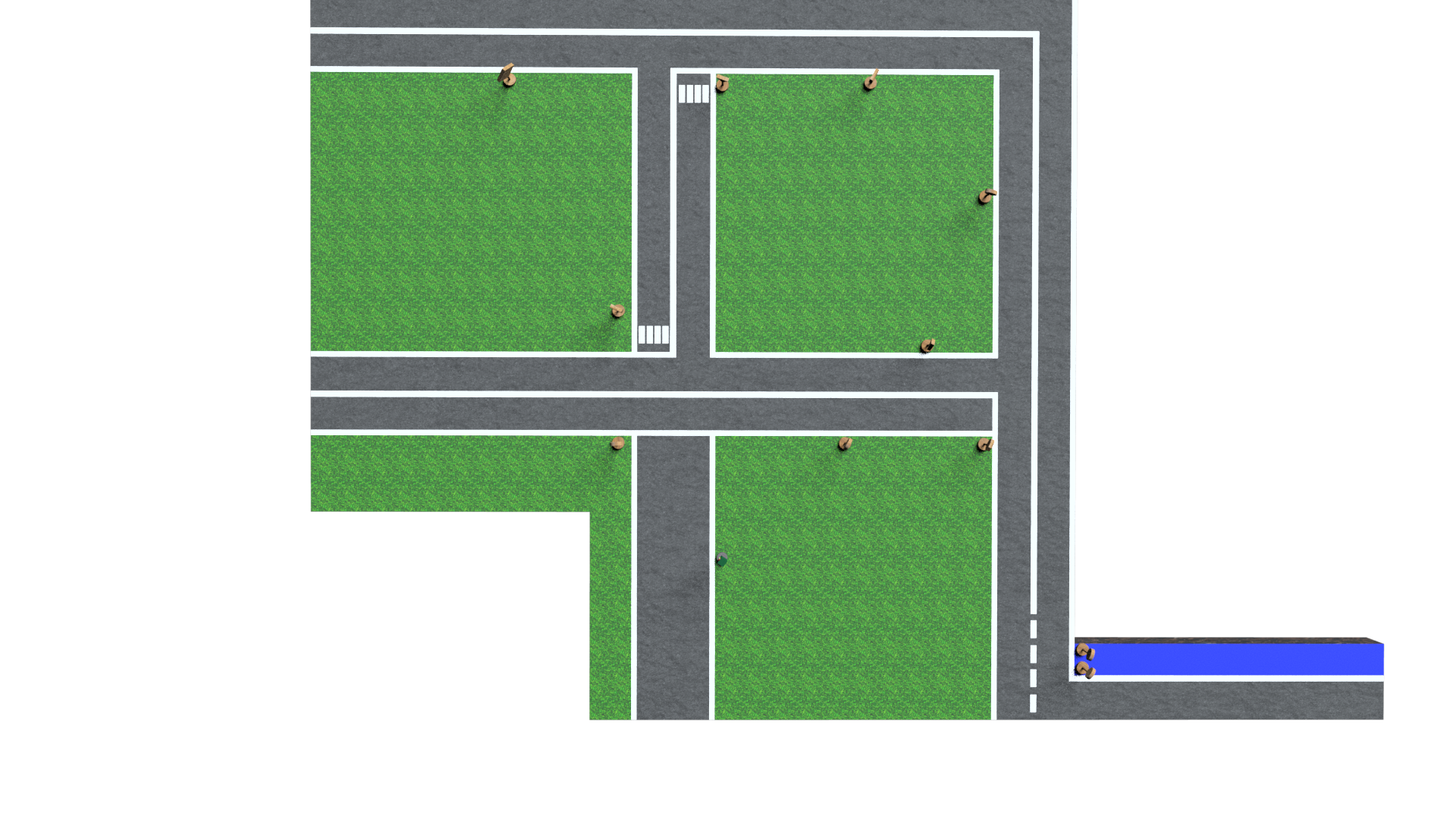
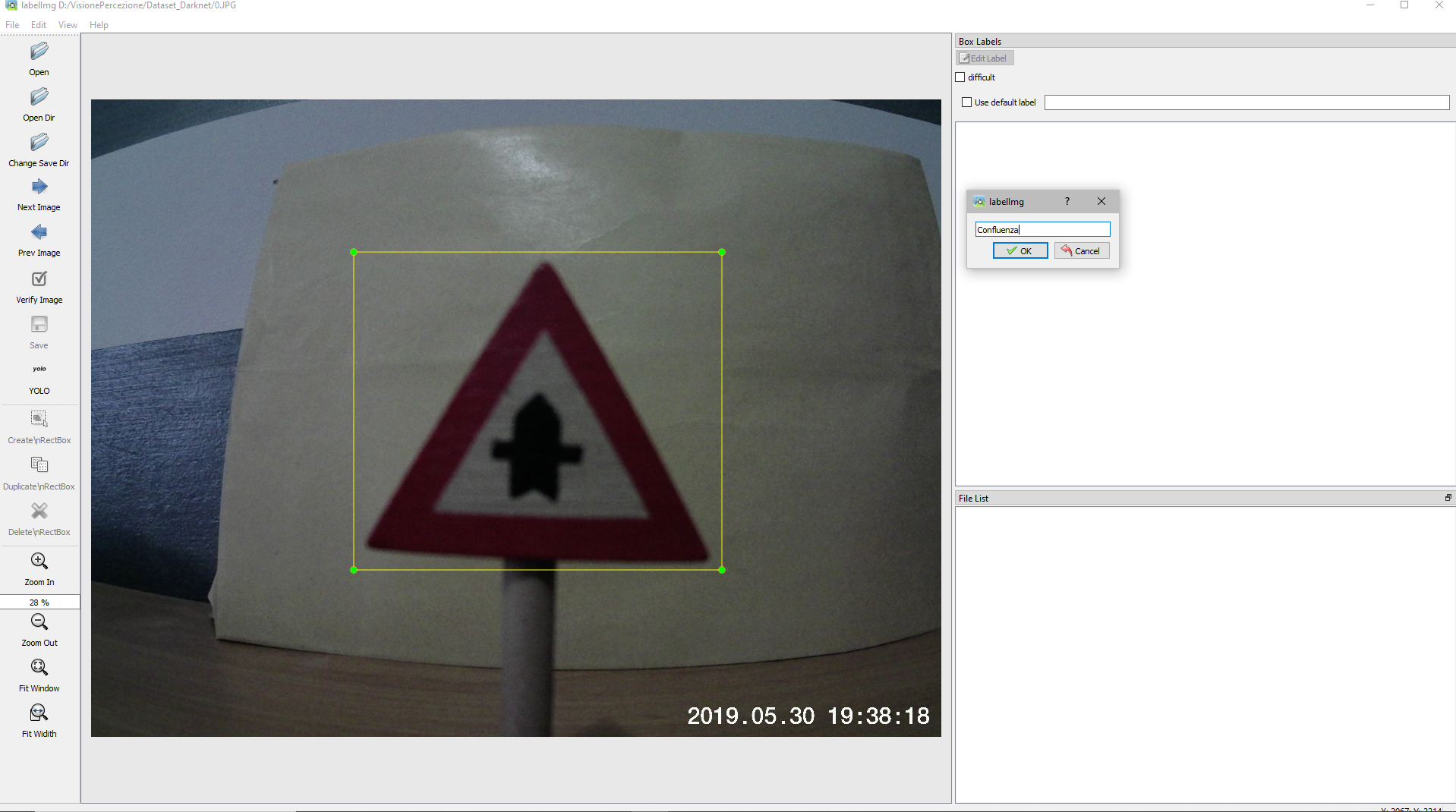
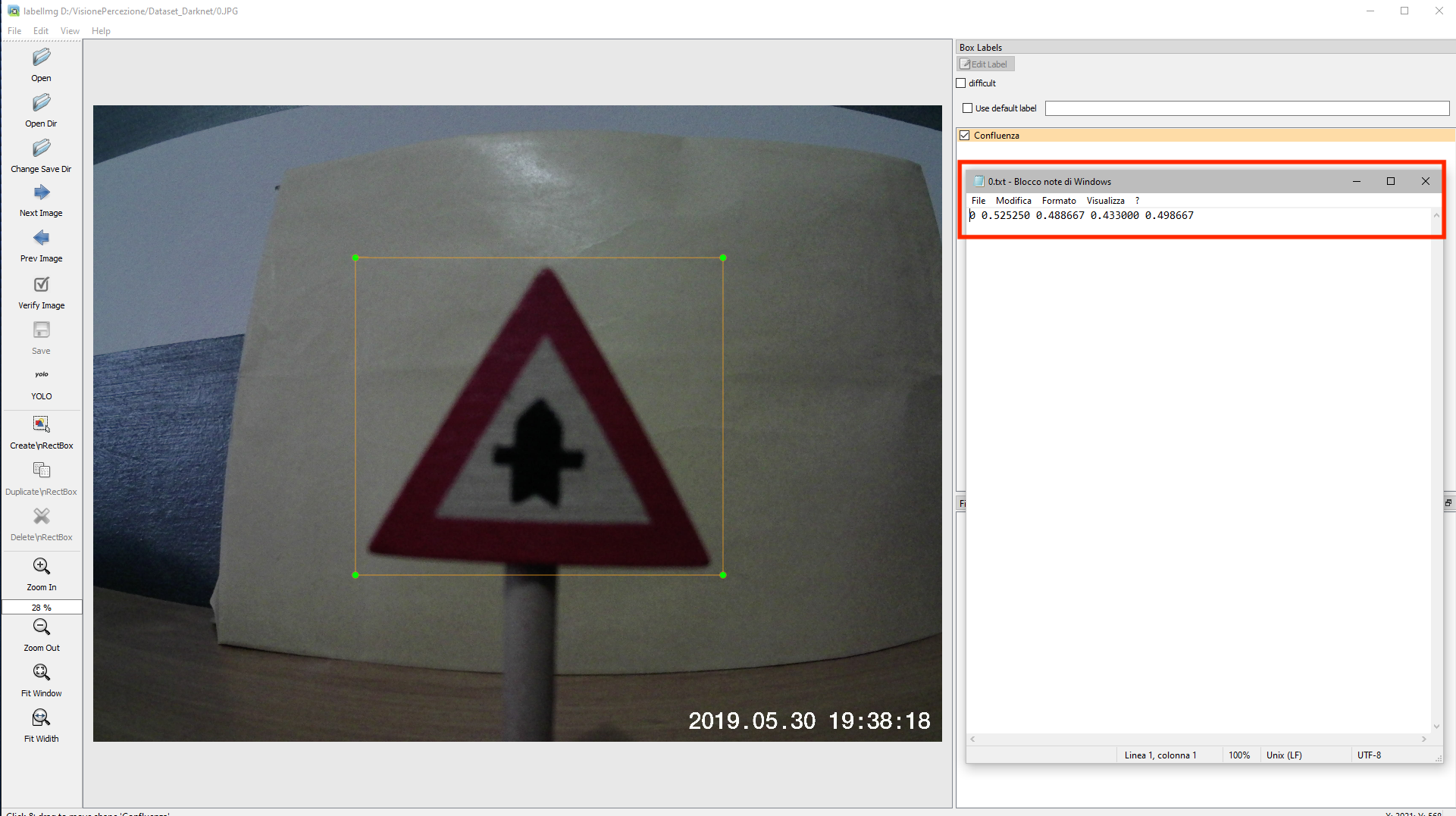
After loading the project folder on the drive, we have created a new Google Colaboratory session for training the neural network.
- in Colaboratory file, need to change the runtime type: from Runtime menu select Change runtime type and choose GPU as Hardware accelerator.
Configuration
In this section we will proceed to configure our Darknet network.
We will proceed to mount Google Drive on the Colab session
from google.colab import drive
print("mounting DRIVE...")
drive.mount('/content/gdrive')
!ln -s /content/gdrive/My\ Drive/root_folder/my_drive
Now we will proceed to clone the repository , we're going to set some configuration parameters such as:
- OPENCV to build with OpenCV;
- GPU to build with CUDA to accelerate by using GPU;
- CUDNN to build with cuDNN v5-v7 to accelerate training by using GPU;
- CUDNN_HALF to speedup Detection 3x, Training 2x;
The next step is the compile.
!git clone https://github.com/AlexeyAB/darknet
%cd darknet
print("activating OPENCV...")
!sed -i 's/OPENCV=0/OPENCV=1/' Makefile
print("engines CUDA...")
!/usr/local/cuda/bin/nvcc --version
print("activating GPU...")
!sed -i 's/GPU=0/GPU=1/' Makefile
print("activating CUDNN...")
!sed -i 's/CUDNN=0/CUDNN=1/' Makefile
print("activating CUDNN_HALF...")
!sed -i 's/CUDNN_HALF=0/CUDNN_HALF=1/' Makefile
print("making...")
!make
To proceed we will load the dataset in order to use it for training.
The idea is to insert in a folder called obj all the images .jpg with the relative files.txt and then compress the folder.
print("loading dataset...)
!cp /my_drive/dataset_folder/obj.zip ../
And now we can unzip it.
print("unziping dataset...")
!unzip ../obj.zip -d data/obj.zip ../
It is important to also load the main yolo-obj.cfg configuration file, which will contain information for the construction of the network, such as the size of the images, the number of classes, filters, any augmentation techniques and more.
The file is located in the folder configuration_files.
The main changes that have been made are shown below:
- change line batch to batch=64
- change line subdivisions to subdivisions=16
- change line max_batches to (classes*2000 but not less than number of training images, but not less than number of training images and not less than 6000): max_batches=28000
- change line steps to 80% and 90% of max_batches: steps=22400,25200
- set network size width=416 height=416 or any value multiple of 32:
- change line classes=14 to your number of objects in each of 3 [yolo]-layers:
- change filters=57 to filters=(classes + 5)x3 in the 3 [convolutional] before each [yolo] layer, keep in mind that it only has to be the last [convolutional] before each of the [yolo] layers.
Darknet needs two more files:
-
obj.names, which contains the name of the classes.
The file must be similar to the one generated during the dataset preparation phase. So it is important to respect the order of the classes..
class 0
class 1
class 2
class 3
class 4
...
- obj.data, which contain information about training and number of classes.
classes = number of classes
train = path_to/train.txt
valid = path_to/valid.txt
names = path_to/obj.names
backup = path_to/backup_folder
For loading configuration files:
print("loading yolo-obj.cfg...")
!cp /my_drive/configuration_files/yolo-obj.cfg ./cfg
print("loading yolo-obj.names..")
!cp /my_drive/configuration_files/yolo-obj.names ./data
print("loading yolo-obj.data..")
!cp /my_drive/configuration_files/yolo-obj.data ./data
Darknet needs a .txt files for training which contains filenames of all images, each filename in new line, with path relative, for example containing:
data/obj/img1.jpg
data/obj/img2.jpg
data/obj/img3.jpg
...
Specifically, we decided to split the dataset in:
- 80% training set
- 10% validation set
- 10% test set
We have defined a Python script that does it: generate_train.py
Then, 3 .txt files are generated and saved on the Drive in the dataset_preparation folder:
- train.txt
- valid.txt
- test.txt
Darknet offers the possibility to stop training at one point and resume it at a second moment:
- if you start the training for the first time you need to save the txt files on the Drive in the specified folder.
- if training is resumed from the point of interruption, the previously saved files must be loaded (to keep the dataset split unaltered)
START TRAINING FROM BEGINNING:
print("loading script...")
!cp /my_drive/py_scripts/generate_train.py ./
print("performing script..")
!python generate_train.py
print("copying .txt in Drive..")
!cp ./data/train.txt /my_drive/dataset_preparation/
!cp ./data/test.txt /my_drive/dataset_preparation/
!cp ./data/valid.txt /my_drive/dataset_preparation/
RESUME TRAINING:
print("loading train.txt...")
!cp /my_drive/dataset_preparation/train.txt ./data
print("loading test.txt...")
!cp /my_drive/dataset_preparation/test.txt ./data
print("loading valid.txt...")
!cp /my_drive/dataset_preparation/valid.txt ./data
For training, you need to download the pre trained weights (yolov4.conv.137) are used to speed up the workout. The approach is to use pre-trained layers to build a different network which may have similarities in the first layers.
This file must be uploaded to the backup folder
print("loading pre_trained weights...")
!cp /my_drive/backup/yolov4.conv.137 ./
Once the configuration phase is complete, it is possible to lead to the training phase
Training
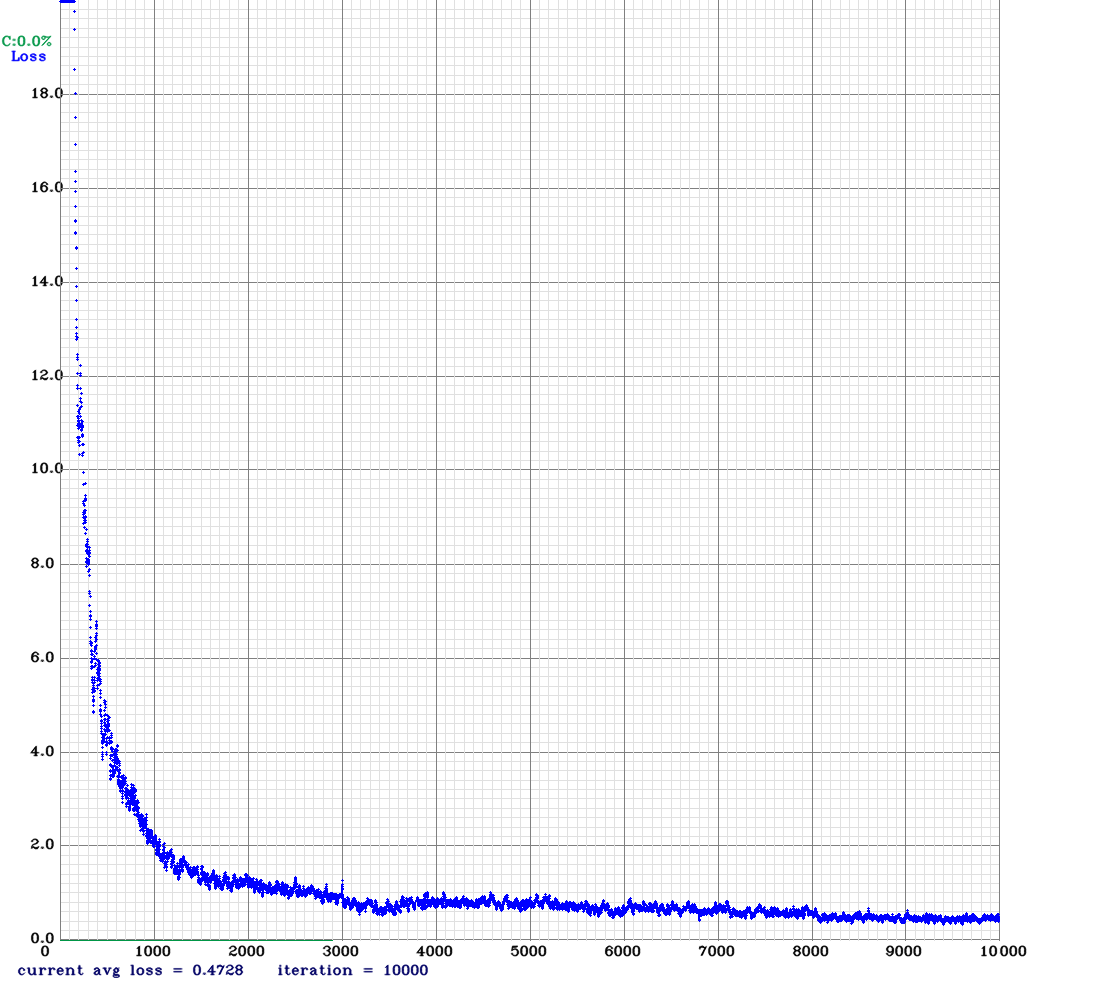
In this section, we will start training the network using the command line:
!./darknet detector train data/obj.data cfg/yolo-obj.cfg yolov4.conv.137 -dont_show
- file yolo-obj_last.weights will be saved to the backup folder for each 100 iterations
- file yolo-obj_xxxx.weights will be saved to the backup folder for each 1000 iterations
It is also possible to stop the training at a point (for example after 2000 iterations) and start again later from it:
!./darknet detector train data/obj.data cfg/yolo-obj.cfg /my_drive/backup/yolo-obj_last.weights -dont_show
Detection
When the training is complete, we will perform object detection on the videos and save the results on the Drive.
- increase network-resolution by set in your .cfg-file height=608 and width=608
- change in obj.data file, from valid = path_to/valid.txt to valid = path_to/test.txt
Run the following command lines:
print("detecting...")
!./darknet detector demo data/obj.data cfg/yolo-obj.cfg /my_drive/backup/yolo-obj_xxxx.weights -dont_show /my_drive/test_videos/name_video -thresh .7 -i 0 -out_filename prediction.avi
print("save prediction in Drive...")
!cp prediction.avi /my_drive/predictions/name_prediction
For the resources Drive of the whole project: Google Drive
For all Python code on Github: YOLODarknet_code.ipynb